Projet : Forêts aléatoires dans un contexte d'apprentissage distribué
État
Terminé (2022)
Type
Baccalauréat
Équipe
- Vincent Latourelle1 (hiver 2022)
- Steven Robidas1 (hiver 2022)
- Olivier Lefebvre1 (hiver 2022)
- Martin Vallières1 (hiver 2022)
1 Départment d’informatique, Université de Sherbrooke, Sherbrooke (QC), Canada
Préambule
Ce projet de fin d’études a été réalisé par Vincent Latourelle et Steven Robidas à la session d’hiver 2022 dans le cadre de leur cheminement au baccalauréat en informatique à l’Université de Sherbrooke. Ce travail a été supervisé par Olivier Lefebvre et Martin Vallières.
Introduction
L’apprentissage automatique est une branche fort utile dans le domaine médical. Par contre, les données médicales ne peuvent pas nécessairement être centralisées pour concevoir des modèles précis. Afin de conserver la confidentialité des données dans l’apprentissage automatique, certains modèles d’apprentissage fédéré, qui permettent d’entrainer des modèles entre plusieurs organisations sans centraliser les données, ont été développés.
Ce projet se concentre sur le modèle de forêt aléatoire (Random Forest) dans un contexte fédéré horizontal. Les articles sur lesquels se base notre implémentation sont «Federated personalized random forest for human activity recognition»¹ et «Federated Extra-Trees With Privacy Preserving»².
Détails d’implémentation
L’implémentation a été faite en Python et Docker a été utilisé pour l’exécution des clients.
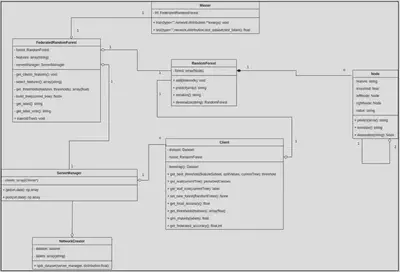
Classes
Dans cette section, les différentes classes implémentées seront décrites.
NetworkCreator
Classe permettant de répartir les données d’un Dataframe entre les clients pour simuler un réseau fédéré. La méthode split_dataset permet de répartir de trois façons différentes:
- Unequal_rep: Répartition divisant en 2 le nombre de données pour chaque client. Exemple pour 5 clients, en pourcentage des données totales: 50%, 25%, 12.5%, 6.25%, 6.25%.
- 2 clients avec data_repartion et sans label_repartition: Sépare les données entre les deux clients en précisant le pourcentage de données utilisées dans le premier client. Le reste va se retrouver dans le deuxième client. La répartition des cibles d’entrainement est conservée.
- 2 clients avec data_repartion et avec label_repartition: Sépare les données entre les deux clients en précisant le pourcentage de données utilisées dans le premier client. Le reste va se retrouver dans le deuxième client. La répartition des cibles d’entrainement pour le client 1 est précisée sous forme de dictionnaire. Par exemple, si le dictionnaire {‘B’: 25, ‘M’:75} est passé en paramètre, 25% des données seront de la cible ‘B’ et 75% de la cible ‘M’.
- Sinon: Les données sont séparées entre tous les clients en conservant les proportions entre les cibles d’entrainement.
ServerManager
Classe qui gère les communications (GET et POST) entre le master et les clients.
Client
Classe qui gère les opérations des clients dans la construction d’une random forest fédérée.
Master
Classe qui sert de point d’entrée du framework pour appeler les différents algorithmes d’entrainement distribués (seulement RandomForest pour l’instant). Cette classe contient 2 méthodes principales, train et test.
La méthode train permet d’entrainer un modèle à l’aide des paramètres type et distribution.
- type: Type de modèle d’apprentissage. Seulement rf pour l’instant.
- distribution: méthode d’entrainement:
- Federated: entraine un modèle de façon distribué.
- Localised: Entraine un modèle chez chaque client et retourne la liste des modèles.
- Centralised: entraine un modèle centralisé.
La méthode test permet d’obtenir les différents types d’accuracy:
- type: Type de modèle d’apprentissage. Seulement rf pour l’instant.
- distribution: méthode de test:
- Federated: Retourne l’accuracy du modèle entrainé de façon distribué. Le modèle est envoyé chez les clients et ceux-ci le teste avec leur ensemble de tests et retourne la valeur au master.
- Localised: Entraine un modèle chez chaque client et retourne l’accuracy sur leur propre ensemble de tests.
- Centralised: retourne l’accuracy du modèle centralisé sur un ensemble de test.
FederatedRandomForest
Classe qui gère le processus d’entrainement d’une random forest en mode fédéré.
RandomForest
Classe qui contient une collection d’arbres de décision afin de faire une prédiction sur l’ensemble de ces arbres à l’aide d’un vote majoritaire.
Node
Classe qui représente un nœud d’un arbre de décision.
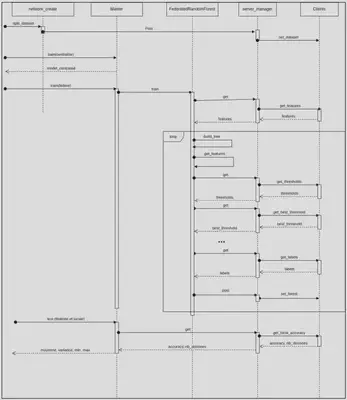
Déroulement de l’algorithme
- Le NetworkCreator répartit les données entre les K clients présents dans le ServerManager.
- Le Master appel la fonction train de sa FederatedRandomForest.
- La FederatedRandomForest demande à un client la liste des features présents dans son ensemble d’entrainement.
- La FederatedRandomForest construit n arbres avec les clients:
- La FederatedRandomForest sélectionne au hasard un certain nombre de features.
- Elle envoie les features sélectionnés aux clients.
- Les clients sélectionnent chacun une valeur située entre l’intervalle des valeurs possibles pour chacun des features obtenus du master, c’est-à-dire une valeur située entre le minimum et le maximum inclusivement pour un feature donné. Ils renvoient ensuite ces valeurs au master (FederatedRandomForest). Les clients séparent initialement leur ensemble d’entrainement en fonction des nœuds présents dans l’arbre actuellement en construction.
- La FederatedRandomForest choisit au hasard une valeur entre le minimum et le maximum des valeurs obtenus des clients pour chaque feature. Elle renvoie ensuite ces valeurs aux clients.
- Les clients choisissent la valeur qui sépare le mieux leur ensemble d’entrainement (à l’aide de Gini) parmi les valeurs obtenues de FederatedRandomForest. Les clients séparent initialement leur ensemble d’entrainement en fonction des nœuds présents dans l’arbre actuellement en construction. Ils renvoient ensuite cette valeur à la FederatedRandomForest ainsi que le nombre de données dans leur ensemble d’entrainement.
- La FederatedRandomForest fait un vote majoritaire pondéré par le nombre de données de chaque client. Elle crée un nœud avec l’attribut sélectionné et construit récursivement les arbres de gauche et de droite.
- Les étapes a à f seront donc répétées jusqu’à ce qu’une certaine profondeur d’arbre soit atteinte ou que le nombre de données chez les clients est insuffisant pour continuer à faire des séparations.
- Lorsque ces critères sont remplis, la FederatedRandomForest demande aux clients d’envoyer la classe majoritaire actuelle. La FederatedRandomForest effectue ensuite un vote majoritaire pondéré par le nombre de données totales dans l’ensemble d’entrainement du client pour construire la feuille de l’arbre.
- La FederatedRandomForest envoie la forêt construite aux clients.
Utilisation
Les détails de l’utilisation sont présentés dans le Readme. (liens vers GitHub)
Résultats
Tous les résultats ont été obtenus avec une moyenne d’exécutions de l’algorithme.
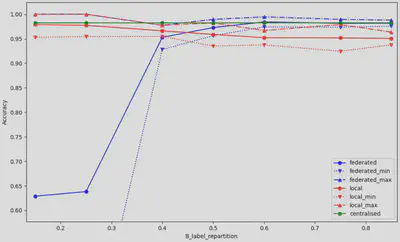
Les résultats présentés à la figure 3 ont été obtenus en faisant varier la répartition des cibles d’entrainement dans le client 1, d’une répartition de 15% de cible ‘B’ et 85% de cible ‘M’ jusqu’à 85% de cible ‘B’ et 15% de cible ‘M’. La répartition initiale des données étant de 60% ‘B’ et 40% ‘M’. Il est possible d’observer une justesse très basse lorsque la quantité de ‘M’ est très élevé pour le client 1. Notre hypothèse est que cette configuration rassemble toutes les données dont la cible est ‘M’ dans le premier client, ce qui impacte négativement l’apprentissage en mode fédéré. À partir de 50% de cible ‘B’, le modèle fédéré semble obtenir de très bons résultats, surpassant l’entrainement local et en obtenant des résultats similaires à l’entrainement centralisé.
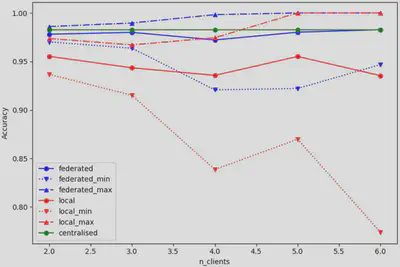
Les résultats présentés à la figure 4 résultent d’un entrainement avec des clients qui possèdent un nombre inégal de données, répartis à l’aide de ‘unequal_rep’ de NetworkCreator. Il est possible d’observer une tendance où la justesse minimale de l’entrainement local diminue et que la justesse moyenne de l’entrainement local diminue aussi, car les clients ont de moins en moins de données. La justesse en mode fédéré semble suivre de près la justesse en mode centralisé. Ces résultats peuvent s’expliquer par le fait que le client 1 possède un poids décisionnel aussi important que l’ensemble des autres clients. Donc, en mode fédéré, cette distribution est similaire à entrainer une forêt aléatoire centralisée, mais avec la moitié des données.
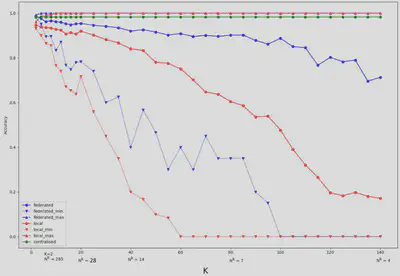
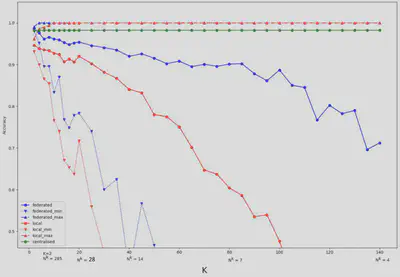
L’accuracy a été mesuré en faisant croitre le nombre de clients, de 2 jusqu’à 140. On peut observer une baisse significative des modèles locaux et du modèle fédéré à mesure que le nombre de clients augmente. Cependant, le modèle fédéré est plus résilient que les modèles locaux. En effet, le modèle fédéré produit une justesse raisonnable (environ 88%) comparativement aux modèles locaux (environ 50%).
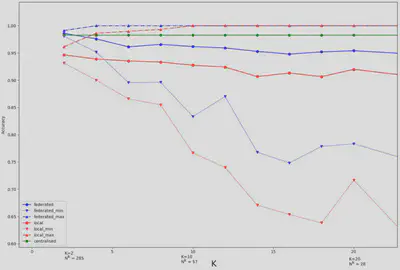
Avec la figure 6, il est possible de voir plus en détail l’impacte du nombre de clients, jusqu’à 20 clients. On observe que le modèle fédéré semble en moyenne être un bon compromis entre le modèle centralisé et les modèles locaux.
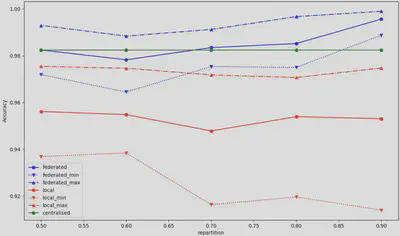
La figure 7 présente l’évolution de la justesse selon le nombre de données dans le premier client (en pourcentage). La répartition des données ne semble pas avoir d’impact significatif sur les performances du modèle.
Travaux futurs et conclusion
La solution permet actuellement d’avoir une hétérogénéité seulement quand deux clients sont utilisés. Il faudrait donc ajouter la possibilité d’avoir de l’hétérogénéité à plus de deux clients pour simuler une situation réelle d’apprentissage fédéré. Il serait aussi intéressant d’analyser les performances du modèle avec des vrais des données provenant de milieux différents à la place de données centralisées qui sont séparées artificiellement. Le framework permet seulement d’entrainer des forêts aléatoires pour l’instant et il faudrait rajouter d’autres modèles pour avoir une solution complète.
En résumé, nous avons conçu un framework d’apprentissage fédéré ainsi qu’un algorithme fédéré de random forest basé sur (1) et (2). Nous avons ensuite analysé l’impact de différentes variations sur les performances du modèle (hétérogénéité et nombre de clients). Il a été possible d’observer que le modèle random forest distribué performait généralement mieux que les modèles locaux, peu importe les variations effectuées.
Bibliographie
(1) Songfeng Liu, Jianyan Wang, Wenliang Zhang, « Federated personalized random forest for human activity recognition », AIMS Press, 22 novembre 2021, https://www.aimspress.com/article/doi/10.3934/mbe.2022044?viewType=HTML
(2) Yang Liu, Mingxim Chen, Wenxi Zhang, Junbo Zhang, Yu Zheng, « Federated Extra-Trees With Privacy Preserving », Arxiv, 18 Février 2020, https://arxiv.org/abs/2002.07323