Thèmes

Contexte
D’autre part, les médecins décrivent et écrivent également les caractéristiques importantes des patients et les symptômes liés à la maladie pour presque chaque consultation médicale par le biais de notes médicales textuelles en forme libre. Ces dernières années, les progrès significatifs de la technologie multi-omique (par exemple, génomique, transcriptomique, etc.) ont également créé des opportunités sans précédent pour caractériser les processus biologiques corrélés aux maladies. Cependant, la combinaison de ces sources de données hétérogènes de manière significative pour la prédiction des maladies est un défi.
Pour une meilleure médecine de précision, les médecins doivent donc désormais prendre des décisions thérapeutiques de plus en plus complexes avec un nombre irréaliste de variables. C’est pourquoi les développements de l’intelligence artificielle (IA) sont envisagés pour créer une révolution de la science des données en médecine. En particulier, les réseaux de neurones graphiques (GNN) ont montré un immense potentiel dans l’apprentissage de représentations de données significatives et puissantes en combinant l’inférence relationnelle des modèles graphiques avec la puissance de l’apprentissage profond. Cependant, étant donné que la puissance de l’apprentissage profond est fortement associée à la taille des données et que les données médicales ne peuvent pas être facilement partagées entre les institutions médicales pour des raisons de confidentialité des patients, le développement de modèles de GNN puissants pour la prédiction des maladies dans le domaine de la santé est un défi majeur.
Mission
- (i) des modèles GNN peuvent être développés à partir des bases de données de plusieurs établissements de santé, augmentant ainsi la taille des données analysées ; et
- (ii) les données sont toujours conservées dans les limites de chaque établissement de santé, évitant ainsi le transfert de données.

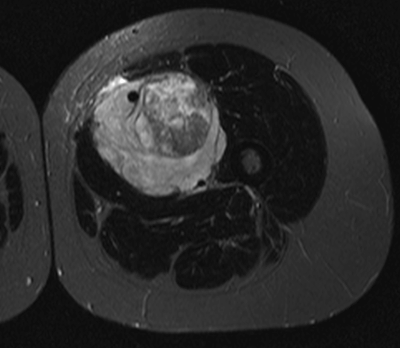
Axe de recherche 1 : Imagerie médicale
Les tumeurs les plus agressives ont tendance à être plus hétérogènes
Les réseaux de neurones permettent détecter les tumeurs les plus hétérogènes
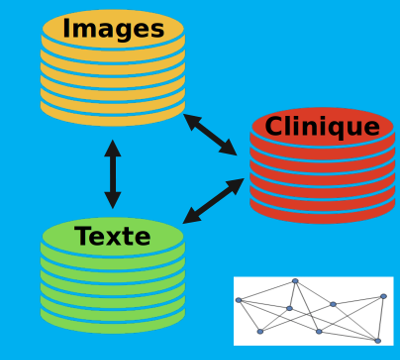
Axe de recherche 2 : Données hétérogènes
Les données de différentes sources peuvent être combinées pour effectuer de meilleures prédictions
Par exemple, l’imagerie médicale, les notes textuelles de médecins et les données cliniques regorgent d’informations pertinentes
Axe de recherche 3 : Apprentissage fédéré
Pour garantir la vie privée des patients tout en s'assurant de pouvoir utiliser un maximum de données probantes
Apprentissage décentralisé permettant d'assurer la souveraineté des centres médicaux

MEDomicsTools
Le laboratoire MEDomics UdeS vise à promouvoir l’utilisation de bonnes pratiques en science des données.

Ce laboratoire est une sous-branche du consortium MEDomics.
Consultez le site de MEDomics Publication principale du consortium