Project: Random forests in a distributed learning context
Status
Completed (2022)
Type
Bachelor’s
Team
- Vincent Latourelle1 (winter 2022)
- Steven Robidas1 (winter 2022)
- Olivier Lefebvre1 (winter 2022)
- Martin Vallières1 (winter 2022)
1 Computer science department, Université de Sherbrooke, Sherbrooke (QC), Canada
Preamble
This final project was realized by Vincent Latourelle and Steven Robidas in the winter 2022 session as part of their bachelor’s degree in computer science at the Université de Sherbrooke. This work was supervised by Olivier Lefebvre and Martin Vallières.
Introduction
Machine learning is a very useful branch in the medical field. However, medical data cannot necessarily be centralized to design accurate models. In order to maintain data privacy in machine learning, some federated learning models, which allow training models across multiple organizations without centralizing the data, have been developed.
This project focuses on the random forest model in a horizontal federated context. The papers on which our implementation is based are “Federated personalized random forest for human activity recognition"¹ and “Federated Extra-Trees With Privacy Preserving"².
Implementation details
The implementation was done in Python and Docker was used to run the clients.
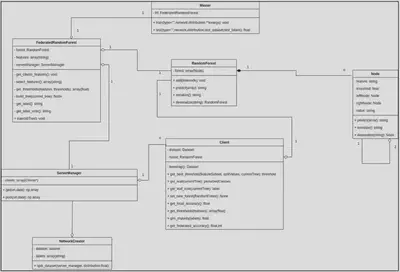
Classes
In this section, the different implemented classes will be described.
NetworkCreator
Class that allows to distribute the data of a Dataframe between the clients to simulate a federated network. The split_dataset method is used to distribute in three different ways:
- Unequal_rep: Distribution dividing the number of data for each client in 2. Example for 5 clients, as a percentage of total data: 50%, 25%, 12.5%, 6.25%, 6.25%.
- 2 clients with data_repartion and without label_repartition: Separates the data between the two clients by specifying the percentage of data used in the first client. The rest will be in the second client. The distribution of the training targets is preserved.
- 2 clients with data_repartion and with label_repartition: Separates the data between the two clients by specifying the percentage of data used in the first client. The rest will be in the second client. The distribution of training targets for client 1 is specified in dictionary form. For example, if the dictionary ‘B’: 25, ‘M’:75} is passed as a parameter, 25% of the data will be from the target ‘B’ and 75% from the target ‘M’.
- Otherwise: The data is separated between all the clients while keeping the proportions between the training targets.
ServerManager
Class that manages communications (GET and POST) between the master and the clients.
Client
Class that manages the operations of the clients in the construction of a federated random forest.
Master
Class that serves as the entry point of the framework to call the different distributed training algorithms (only RandomForest for the moment). This class contains 2 main methods, train and test.
The train method allows to train a model using the type and distribution parameters.
- type: Type of training model. Only rf for the moment.
- distribution: training method:
- Federated: Train a model in a distributed way.
- Localised: Train a model at each client and return the list of models.
- Centralized: trains a centralized model.
The test method allows to obtain the different types of accuracy:
- type: Type of training model. Only rf for the moment.
- distribution: test method:
- Federated: Returns the accuracy of the model trained in a distributed way. The model is sent to the clients and they test it with their test set and return the value to the master.
- Localised: Trains a model at each client and returns the accuracy on their own test set.
- Centralized: Returns the accuracy of the centralized model on a test set.
FederatedRandomForest
Class that manages the training process of a random forest in federated mode.
RandomForest
Class that contains a collection of decision trees in order to make a prediction on the set of these trees using a majority vote.
Node
Class that represents a node of a decision tree.
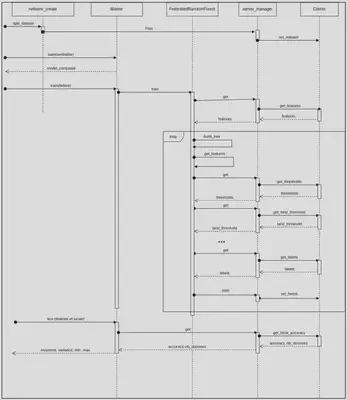
Flow of the algorithm
- The NetworkCreator distributes the data among the K clients in the ServerManager.
- The Master calls the train function of his FederatedRandomForest.
- The FederatedRandomForest asks a client for the list of features present in its training set.
- The FederatedRandomForest builds n trees with clients:
- The FederatedRandomForest randomly selects a number of features.
- It sends the features selected to the clients.
- Clients each select a value between the range of possible values for each of the features obtained from the master, i.e., a value between the minimum and maximum inclusive for a given feature. They then return these values to the FederatedRandomForest master. Clients initially separate their training set according to the nodes present in the tree currently under construction.
- The FederatedRandomForest randomly chooses a value between the minimum and maximum values obtained from the clients for each feature. It then returns these values to the clients.
- Clients choose the value that best separates their training set (using Gini) from the values obtained from FederatedRandomForest. Clients initially separate their training set based on the nodes present in the tree currently under construction. They then return this value to FederatedRandomForest along with the number of data in their training set.
- The FederatedRandomForest does a majority vote weighted by the number of data items for each client. It creates a node with the selected attribute and recursively builds the left and right trees.
- Steps a to f will therefore be repeated until a certain tree depth is reached or the number of data at the clients is insufficient to continue making separations.
- When these criteria are met, FederatedRandomForest asks clients to send the current majority class. FederatedRandomForest then performs a majority vote weighted by the number of total data in the client's training set to build the tree leaf.
- FederatedRandomForest sends the constructed forest to clients.
Usage
The details of the usage are presented in the Readme. (links to GitHub)
Results
All results were obtained with an average of executions of the algorithm.
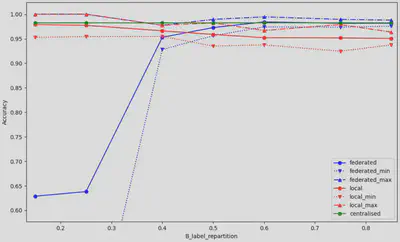
The results shown in Figure 3 were obtained by varying the distribution of training targets in client 1 from a distribution of 15% ‘B’ target and 85% ‘M’ target to 85% ‘B’ target and 15% ‘M’ target. The initial distribution of the data was 60% ‘B’ and 40% ‘M’. It is possible to observe a very low accuracy when the amount of ‘M’ is very high for client 1. Our hypothesis is that this configuration gathers all the data whose target is ‘M’ in the first client, which negatively impacts the learning in federated mode. À 50% target ‘B’ and above, the federated model seems to perform very well, outperforming local training and achieving similar results to centralized training.
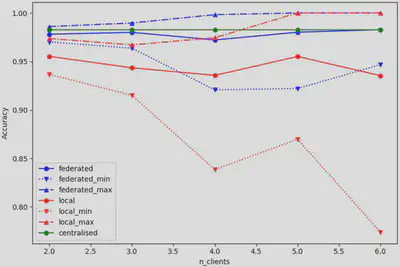
The results shown in Figure 4 are the result of training with clients that have an unequal amount of data, distributed using ‘unequal_rep’ from NetworkCreator. It is possible to observe a trend where the minimum correctness of local training decreases and the average correctness of local training also decreases, as clients have less and less data. The federated mode accuracy seems to closely follow the centralized mode accuracy. These results can be explained by the fact that client 1 has as much decisional weight as all the other as all the other clients. Thus, in federated mode, this distribution is similar to training a centralized random forest, but with half the data.
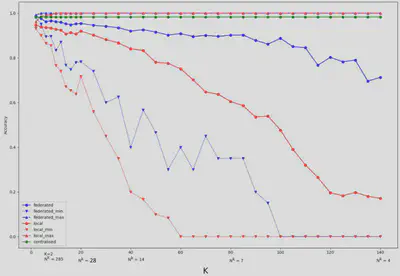
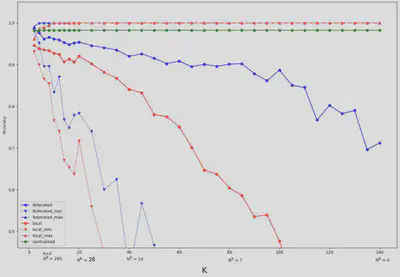
Accuracy was measured by increasing the number of clients from 2 to 140. We can observe a significant decrease in the local and federated models as the number of clients increases. However, the federated model is more resilient than the local models. Indeed, the federated model produces reasonable correctness (about 88%) compared to the local models (about 50%).
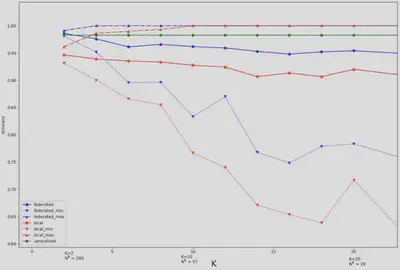
With figure 6, it is possible to see in more detail the impact of the number of clients, up to 20 clients. We observe that the federated model seems on average to be a good compromise between the centralized model and the local models.
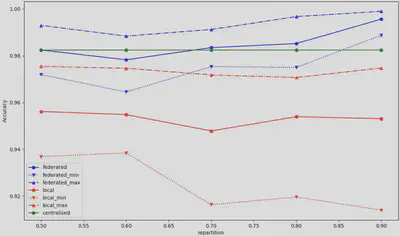
Figure 7 shows the change in accuracy by number of data in the first client (in percent). The distribution of data does not seem to have a significant impact on the performance of the model.
Future work and conclusion
The solution currently allows heterogeneity only when two clients are used. It would therefore be necessary to add the possibility of having heterogeneity at more than two clients to simulate a real situation of federated learning. It would also be interesting to analyze the performance of the model with real data from different environments instead of centralized data that are artificially separated. The framework can only train random forests for the moment and other models would have to be added to have a complete solution.
In summary, we have designed a federated learning framework and a federated random forest algorithm based on (1) and (2). We then analyzed the impact of different variations on the performance of the model (heterogeneity and number of clients). It was possible to observe that the distributed random forest model generally performed better than the local models, regardless of the variations made.
Bibliography
(1) Songfeng Liu, Jianyan Wang, Wenliang Zhang, « Federated personalized random forest for human activity recognition », AIMS Press, November 22, 2021, https://www.aimspress.com/article/doi/10.3934/mbe.2022044?viewType=HTML
(2) Yang Liu, Mingxim Chen, Wenxi Zhang, Junbo Zhang, Yu Zheng, « Federated Extra-Trees With Privacy Preserving », Arxiv, February 18, 2020, https://arxiv.org/abs/2002.07323